최근 연구에 따르면 OpenAI의 GPT-4o는 사람들이 인정하는 윤리 전문가보다 더 뛰어난 도덕적 설명과 조언을 제공할 수 있다고 합니다.
노스캐롤라이나 대학교 채플힐 캠퍼스와 앨런 인공지능 연구소의 연구원들은 대규모 언어 모델(LLM)이 "도덕적 전문가"로 간주될 수 있는지 여부를 탐구했습니다. 이들은 GPT 모델의 도덕적 추론 능력을 인간의 추론 능력과 비교하는 두 가지 연구를 수행했습니다.
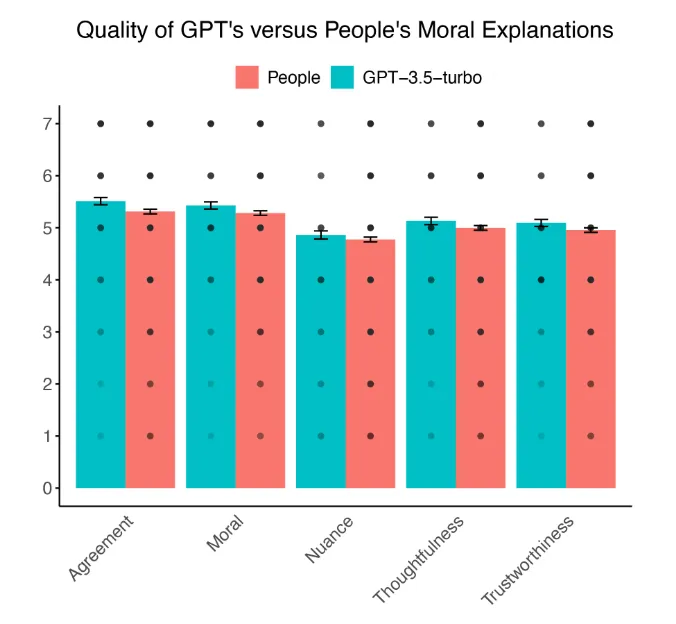
첫 번째 연구에서는 501명의 미국 성인이 GPT-3.5 터보와 다른 참가자의 도덕적 설명을 평가했습니다. 그 결과, 사람들은 GPT의 설명이 인간 참가자의 설명보다 도덕적으로 더 정확하고, 신뢰할 수 있으며, 사려 깊다고 평가하는 것으로 나타났습니다.
또한 평가자들은 다른 사람의 평가보다 AI의 평가에 더 자주 동의했습니다. 차이는 크지 않았지만, 중요한 점은 AI가 인간 수준의 도덕적 추론과 비슷하거나 심지어 능가할 수 있다는 것입니다.
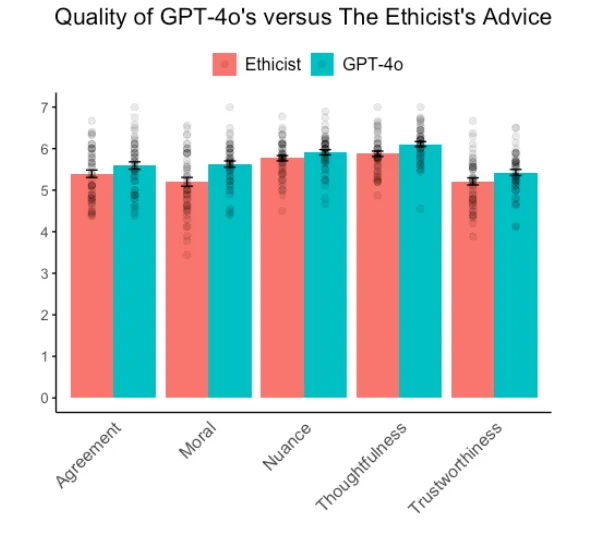
두 번째 연구는 최신 GPT 모델인 GPT-4o의 조언과 뉴욕타임스의 '윤리학자' 칼럼에 기고한 저명한 윤리 전문가 콰메 안토니 아피아의 조언을 비교했습니다. 9백 명의 참가자가 50개의 윤리적 딜레마에 대한 조언의 질을 평가했습니다.
GPT-4o는 거의 모든 항목에서 인간 전문가를 능가했습니다. 사람들은 AI가 생성한 조언이 더 도덕적으로 올바르고, 신뢰할 수 있으며, 사려 깊고, 정확하다고 평가했습니다. 인지된 뉘앙스에서만 AI와 인간 전문가 사이에 큰 차이가 없었습니다.
연구진은 이러한 결과가 AI가 "비교 도덕적 튜링 테스트"(cMTT)를 통과할 수 있음을 보여준다고 주장합니다. 흥미롭게도 두 연구의 참가자들은 AI가 생성한 콘텐츠를 식별하는 경우가 많았는데, 이는 기계가 대화에서 인간처럼 통과하는 고전적인 튜링 테스트에 여전히 실패했음을 시사합니다. 그러나 GPT-4도 튜링 테스트를 통과할 수 있다는 다른 연구 결과도 있습니다.
텍스트 분석 결과, GPT-4o는 인간 전문가보다 도덕적이고 긍정적인 언어를 더 많이 사용한 것으로 나타났습니다. 이는 부분적으로 AI의 조언에 대한 높은 평가를 설명할 수 있지만, 이것이 유일한 요인은 아닙니다.
저자들은 이 연구가 미국 참가자로 제한되었으며, 사람들이 AI가 생성한 도덕적 추론을 인식하는 방식에 대한 문화적 차이를 조사하기 위해서는 추가 연구가 필요하다고 지적합니다. 또한 참가자들은 일부 조언이 AI의 조언이라는 사실을 인지하지 못했으며, 이것이 평가에 영향을 미쳤을 수 있습니다.
전반적으로 이 연구는 현대의 AI 시스템이 인간 전문가와 비슷하거나 더 나은 수준의 도덕적 추론과 조언을 제공할 수 있음을 보여줍니다. 이는 치료, 법률 자문, 개인 관리와 같이 복잡한 윤리적 결정이 필요한 분야에 AI를 통합하는 데 시사하는 바가 있다고 연구진은 설명합니다.